{kind=link}
Self-Hosted Enterprise AI Architecture with n8n, Docker, Ollama, and Vector Databases
As enterprises move beyond the experimental phase of Generative AI, the limitations of public API-based models, specifically regarding data sovereignty, latency, and cost predictability, have become evident. This reference architecture defines a robust, self-hosted AI orchestration and inference environment designed for security-conscious organizations. By utilizing n8n for orchestration, Ollama for local inference, and Qdrant for semantic memory, we establish a private Retrieval-Augmented Generation (RAG) pipeline entirely within the corporate perimeter.
High-Level Architecture Overview
The architecture follows a modular, containerized approach, leveraging Docker as the primary runtime environment. It is designed to isolate sensitive data while providing the flexibility to scale individual components based on computational demand.
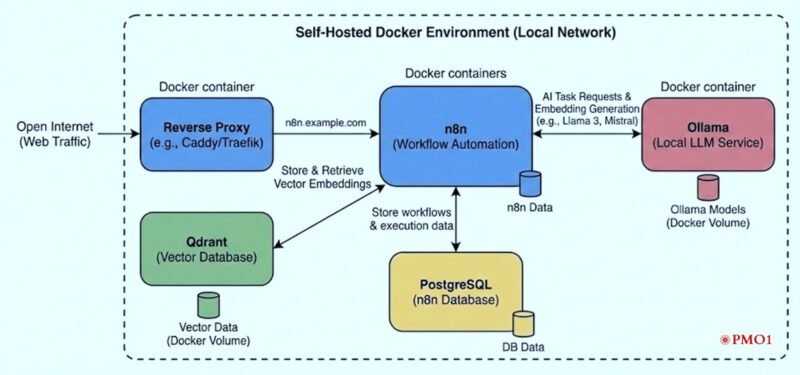
Logical vs. Physical Layers
-
Ingress Layer: Managed by a reverse proxy, handling external-to-internal traffic routing and encryption.
-
Orchestration Layer (Control Plane): n8n acts as the central logic engine, coordinating state and data flow between disparate services.
-
Inference Layer (Data Plane): Ollama serves as the local LLM runtime, processing high-compute tasks without external egress.
-
Storage Layer: Segmented into relational state (PostgreSQL) and high-dimensional vector embeddings (Qdrant).
System Goals
-
Data Sovereignty: Zero data leakage to third-party LLM providers.
-
Architectural Modularity: Components can be swapped (e.g., replacing Qdrant with Pinecone or Milvus) without re-engineering the orchestration logic.
-
Operational Resilience: Persistent storage via Docker volumes ensuring state recovery after container restarts.
Component-by-Component Technical Breakdown
Reverse Proxy (Caddy / Traefik)
The Reverse Proxy acts as the solitary gateway into the environment. While the diagram assumes a local network context, enterprise deployments must treat this as the Policy Enforcement Point (PEP).
-
TLS Termination: Ensures all traffic to the n8n UI and API is encrypted.
-
Service Isolation: The proxy exposes only the necessary n8n ports, keeping the Vector DB, PostgreSQL, and Ollama APIs unreachable from the open internet or broader corporate VLANs.
-
Request Filtering: Implements rate-limiting and basic auth/OIDC integration to protect the orchestration engine.
n8n (Workflow Orchestration Layer)
n8n serves as the Control Plane. Unlike rigid code-based frameworks, n8n provides a visual, node-based environment that simplifies complex AI agentic workflows.
-
API Orchestration: It bridges the gap between enterprise systems (ERP, CRM) and the AI inference layer.
-
State Management: Each workflow execution is tracked, allowing for auditability—a critical requirement for regulated industries.
-
Multi-Model Routing: n8n can logic-gate requests, sending simple tasks to smaller models (e.g., Mistral) and complex reasoning to larger ones (e.g., Llama 3).
Ollama (Local LLM Runtime)
Ollama provides the inference abstraction layer. It manages the lifecycle of local LLMs, providing a standardized OpenAI-compatible API.
-
Model Lifecycle: Models are stored in Docker Volumes, ensuring that multi-gigabyte weights are not redownloaded on container recreation.
-
Resource Management: In a production environment, this component is the most resource-intensive, requiring dedicated GPU passthrough (NVIDIA Container Toolkit) to meet enterprise SLAs for token-per-second (TPS) throughput.
Vector Database (Qdrant)
For RAG-based systems, Qdrant provides the “long-term memory.”
-
Embedding Storage: It stores high-dimensional vectors generated from internal documentation.
-
Semantic Retrieval: n8n queries Qdrant to find relevant context before sending a prompt to Ollama, significantly reducing LLM hallucinations.
-
Persistence: High-speed indexing is maintained via persistent volumes to prevent data loss.
PostgreSQL (Operational State)
While n8n can run on SQLite, an enterprise-grade deployment demands PostgreSQL.
-
Concurrency: Handles high-volume workflow execution data and binary storage.
-
Backup/Recovery: Enables standard DB backup procedures (WAL logs, pg_dump) to ensure the orchestration logic and history are protected.
Data Flow & Interaction Patterns
A typical RAG (Retrieval-Augmented Generation) request follows this sequence:
-
Ingress: A user or external system hits the Reverse Proxy, which routes the request to the n8n API.
-
Preprocessing: n8n cleans the input and sends the query to Ollama‘s embedding model to generate a vector representation of the query.
-
Semantic Search: n8n takes the vector and queries Qdrant for the top-K most relevant document chunks.
-
Prompt Augmentation: n8n constructs a final prompt: “Using the following context [Context from Qdrant], answer the user question [Original Query].”
-
Inference: This augmented prompt is sent to Ollama (e.g., Llama 3).
-
Persistence: The interaction is logged in PostgreSQL for auditing, and the response is returned through the Reverse Proxy.
Security Architecture & Trust Boundaries
The core strength of this design is the Hardened Perimeter.
-
Network Segmentation: All communication between n8n, Ollama, and Qdrant occurs on a private Docker bridge network. These services should not bind to host ports
0.0.0.0, ensuring they are only accessible via the proxy or internally. -
Secrets Management: Environment variables (e.g.,
POSTGRES_PASSWORD,N8N_ENCRYPTION_KEY) should be injected via Docker Secrets or an external vault, never hardcoded in Compose files. -
Auditability: Because n8n stores every execution step in PostgreSQL, the security team can reconstruct exactly what data was retrieved and what the LLM responded, meeting compliance requirements for AI transparency.
Scalability, Reliability & Operations
Scaling the Inference Layer
The primary bottleneck is Ollama. In high-load scenarios, Ollama should be moved to a dedicated node with multiple A100/H100 GPUs. n8n can then connect to this externalized Ollama instance via the internal network.
Persistence Strategy
Statelessness is a myth in AI.
-
Vector Data: Qdrant volumes require high-IOPS storage (NVMe) to maintain low-latency similarity searches.
-
Workflow State: PostgreSQL should be configured with a standard retention policy to prune old execution logs, preventing disk exhaustion.
Common Architectural Variations & Extensions
-
GPU Acceleration: For production, modify the
docker-composeto includedeploy.resources.reservations.devicesfor NVIDIA GPUs. -
Object Storage: For large-scale document processing, integrate MinIO alongside n8n for handling unstructured files (PDFs, images) before they are vectorized.
-
Kubernetes Migration: While Docker is excellent for single-node deployment, this architecture maps directly to K8s deployments using Helm charts for each component, utilizing
Ingresscontrollers in place of the Reverse Proxy.
Why This Architecture Works
This reference architecture provides a balance between deployment velocity and enterprise-grade control. By decoupling the orchestration (n8n), the inference (Ollama), and the memory (Qdrant), architects can iterate on LLM models without disrupting the underlying business logic. Most importantly, it satisfies the “Privacy-First” mandate, ensuring that an organization’s intellectual property remains within its controlled infrastructure.
—————————
PMO1 is the Local AI Agent Suite built for the sovereign enterprise. By deploying powerful AI agents directly onto your private infrastructure, PMO1 enables organizations to achieve breakthrough productivity and efficiency with zero data egress. We help forward-thinking firms lower operational costs and secure their future with an on-premise solution that guarantees absolute control, compliance, and independence. With PMO1, your data stays yours, ensuring your firm is compliant, efficient, and ready for the future of AI.