{kind=link}
The Architect’s Guide to Chunking Strategies in Procurement AI
In the race to operationalize Generative AI, Procurement stands as a frontier of immense untapped value. However, the path from raw data to actionable intelligence – your chunking strategies – is obstructed by a fundamental architectural challenge: Context.
Procurement data is notoriously dense. Master Services Agreements (MSAs), intricate tiered pricing tables, and multi-jurisdictional compliance documents do not fit neatly into the limited context windows of Large Language Models (LLMs). The effectiveness of your Retrieval-Augmented Generation (RAG) architecture, and ultimately, your ROI – hinges on a single, often overlooked variable: your Chunking Strategy.
For the Chief Procurement Officer (CPO) and the CIO alike, chunking is not merely a technical configuration; it is the logic that dictates whether your AI hallucinates a liability clause or accurately flags a supply chain risk.
Context-Aware Procurement Intelligence
To treat chunking as a mere data processing step is a strategic error. It must be viewed as the cognitive filtration system of your AI stack. This Context-Aware Procurement Intelligence moves beyond simple text splitting to prioritize the semantic integrity of procurement documents.
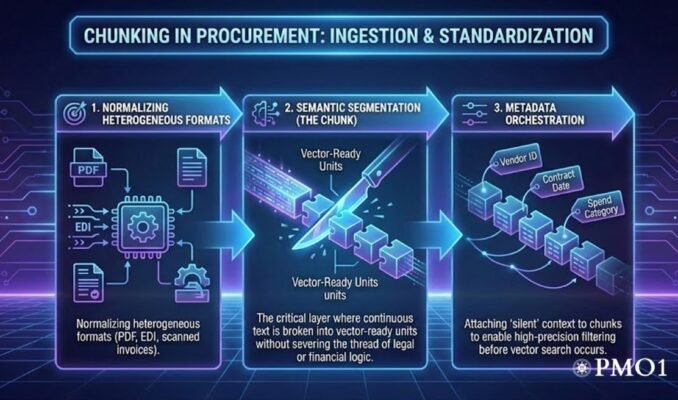
The goal is to ensure that when an LLM retrieves a clause regarding “Force Majeure,” it also retrieves the dependent definition of “Natural Disaster” located twenty pages earlier.
Chunking Strategies for the Supply Chain
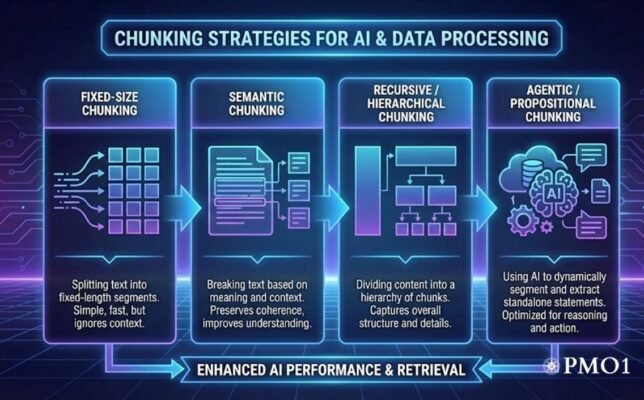
There is no “one-size-fits-all” chunking method for procurement. A standard fixed-size chunk might suffice for general internal wikis, but it will fail catastrophically when applied to a tabular pricing schedule in a supplier contract.
Strategic Recommendations: Operationalizing the Architecture
To transition from pilot to production, digital leadership must mandate a rigorous approach to data architecture. Based on our deployment experience across complex supply chains, we recommend the following execution roadmap:
1. Adopt a “Hybrid-Semantic” Default for Contracts
Do not rely on fixed-size chunking for legal documents. Contracts are structured hierarchically (Article, Section, Clause). Use a Recursive approach that respects document headers. When an analyst queries “Termination for Cause,” the system must retrieve the specific clause plus the preamble identifying the parties involved.
2. Implement “Table-Aware” Parsing
Procurement runs on tables: pricing schedules, distinct SKU lists, and delivery timelines. Standard chunking linearizes tables, turning structured data into nonsense. Deploy dedicated parsing algorithms (such as vision-language models or Markdown converters) that preserve tabular structure within the vector embedding.
3. Enforce Metadata Enrichment at the Source
A chunk without metadata is a needle in a haystack. Before a chunk enters your Vector Database, it must be tagged with:
-
Supplier Entity: (e.g., “Acme Corp”)
-
Effective Date: (e.g., “2026-01-01”)
-
Document Type: (e.g., “SOW,” “NDA”)
-
Region: (e.g., “EMEA”)
-
Spend Category: (e.g., “IT Services”)
(Note: This allows “Pre-filtering,” drastically improving retrieval accuracy.)
4. Optimize for “The Lost in the Middle” Phenomenon
LLMs often focus on the beginning and end of their context window, ignoring information buried in the middle. When retrieving multiple chunks for a summary (e.g., “Summarize all risks in this 100-page agreement”), re-rank the retrieved chunks so that the most semantically relevant information appears at the start and end of the prompt injected into the LLM.
5. Establish a “Ground Truth” Evaluation Set
You cannot manage what you do not measure. Establish a dataset of 50-100 “Golden QA pairs” (e.g., “What is the payment term for Vendor X?”). Use automated evaluation frameworks (like RAGAS or TruLens) to continuously score your chunking strategy against metrics like Context Recall (did we find the right chunk?) and Faithfulness (did the LLM stick to the data?).
6. Leverage Orchestration
Building this architecture from scratch requires significant engineering overhead. For organizations seeking to accelerate time-to-value, tools offers the requisite orchestration layer. By integrating advanced parsing logic with enterprise-grade vector management, some of these tools ensure that your procurement data remains actionable, compliant, and architecturally sound.
Precision as a Competitive Advantage
In the digital procurement landscape, the organizations that win will not be those with the largest data lakes, but those with the highest retrieval fidelity.
Chunking is the mechanism that translates the “noise” of global supply chains into the “signal” of strategic decision-making. By moving beyond basic text splitting and adopting a semantic, metadata-rich strategy, leaders can unlock the true cognitive potential of AI, turning the procurement function into a predictive, value-generating engine.
The technology is ready. The data is waiting. The strategy is yours to define.
—————————
PMO1 is the Local AI Agent Suite built for the sovereign enterprise. By deploying powerful AI agents directly onto your private infrastructure, PMO1 enables organizations to achieve breakthrough productivity and efficiency with zero data egress. We help forward-thinking firms lower operational costs and secure their future with an on-premise solution that guarantees absolute control, compliance, and independence. With PMO1, your data stays yours, ensuring your firm is compliant, efficient, and ready for the future of AI.