{kind=link}
Embedding Strategies for Procurement AI Agents
The initial wave of Generative AI in the enterprise was defined by “width” (e.g. How many users could access a model. The current phase is defined by “depth” : how deeply an AI Agent understands the proprietary reality of the business. For the Chief Procurement Officer (CPO) and the CIO, this presents a specific architectural challenge. A standard Large Language Model (LLM) knows everything about the internet up to its training cutoff, but it knows nothing about your negotiated rate cards, your specific supplier risk taxonomies, or the force majeure clause in your contract with a Tier-1 chip manufacturer.
Without access to this private data, an AI Agent is merely a creative writer, prone to hallucination and practically useless for high-stakes procurement decisions.
The solution is Retrieval-Augmented Generation (RAG), powered by Vector Embeddings. This is the technical strategy of converting unstructured procurement data (contracts, emails, spend logs) into mathematical vectors that Agents can “reason” against.
To build an autonomous Procurement function, leaders must move beyond simple “search” and develop robust Embedding Strategies. It is not enough to have data; your Agents must be able to retrieve the exact semantic context required to execute a workflow autonomously and accurately.
The “Context Gap” in Enterprise AI
While 74% of procurement leaders view Generative AI as a top priority (Gartner), early pilots often fail to scale. The primary failure mode is not the reasoning capability of the AI, but the context retrieval capability of the architecture. The question is: Can Procurement AI Agents help?
The Unstructured Data Trap
Procurement sits on an ocean of unstructured data that traditional ERPs cannot process:
-
Contract PDFs: Thousands of pages of legal text where “payment terms” might be buried in addendums.
-
Supplier Emails: Critical negotiation history locked in inboxes.
-
Market Intelligence: External reports on commodity volatility.
When an AI Agent is asked, “What is our exposure to lithium pricing in APAC?”, a standard model fails. It hallucinates a generic answer. To answer correctly, it must retrieve specific clauses from 50 different contracts and cross-reference them with the latest supplier emails.
The Failure of Keyword Search
Legacy document search (Ctrl+F) fails in the era of Agents.
-
If a user asks about “contingency plans,” but the contract uses the phrase “business continuity,” a keyword search misses the link.
-
The Cost: A prior study from McKinsey estimated that knowledge workers spend 19% of their time searching for information. For AI Agents, “missing information” isn’t just a delay, it’s a critical error. An Agent that misses a renewed compliance certificate might inadvertently block a compliant supplier.
The Trust Barrier
You cannot automate high-value tasks (like invoice reconciliation or tail-spend negotiation) if you cannot trust the Agent’s data source.
-
Hallucination Risk: Without RAG, LLMs make up facts to fill gaps.
-
Citation Necessity: A Procurement Agent must be able to say: “I recommend rejecting this price increase because Clause 4.2 of the Master Services Agreement limits hikes to CPI + 2%.”
This level of precision requires a sophisticated Embedding Strategy.
What is Embedding? (The RAG Architecture)
In the context of AI Agent Orchestration, “Embedding” refers to the process of turning text into numbers (vectors) to create a Semantic Memory for your digital workforce.
1. The Technical Concept: Vector Embeddings
Computers do not understand words; they understand numbers. An Embedding Model takes a chunk of text (e.g., a supplier capability statement) and converts it into a long list of numbers (a vector).
-
Conceptually: Imagine a 3D map. The word “Apple” is placed near “Pear” (fruit context) but also near “iPhone” (tech context).
-
In Procurement: An embedding model learns that “RFP,” “Tender,” and “Solicitation” are semantically identical. It understands that “Net 30” is a payment term, not a fishing net.
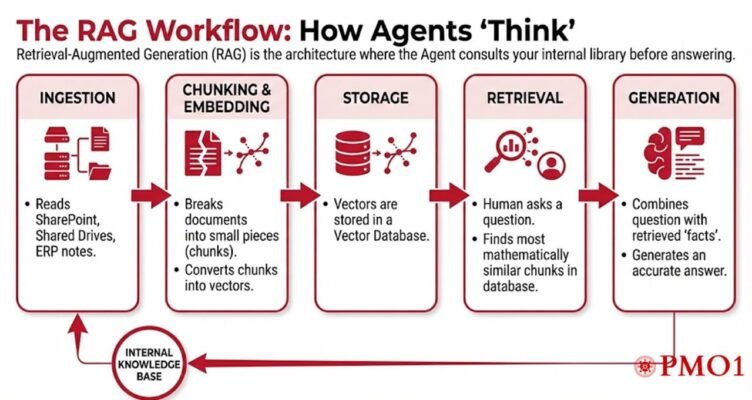
2. The RAG Workflow: How Agents “Think”
Retrieval-Augmented Generation (RAG) is the architecture where the Agent consults your internal library before answering.
-
Ingestion: The system reads your SharePoint, Shared Drives, and ERP notes.
-
Chunking & Embedding: It breaks documents into small pieces (chunks) and converts them into vectors.
-
Storage: These vectors are stored in a Vector Database.
-
Retrieval: When a human asks a question, the system finds the most mathematically similar chunks in the database.
-
Generation: The Agent combines the user’s question with the retrieved “facts” to generate an accurate answer.
3. Why Orchestration Matters
A single RAG pipeline is manageable. But a Procurement organization has hundreds of potential data sources and dozens of specialized Agents.
-
The Governance Agent needs access to legal embeddings.
-
The Sourcing Agent needs access to spend category embeddings.
PMO1 acts as the Orchestration Layer for these RAG workflows. Instead of building a separate RAG stack for every bot, PMO1 provides a unified Semantic Layer. It manages the ingestion of data, the privacy controls (who can see which embedding), and the retrieval logic.
[Conceptual Diagram: The RAG Orchestration Layer]
-
Left: Unstructured Data (PDFs, Emails).
-
Center: PMO1 Embedding Engine (Chunking, Vectorizing, Indexing).
-
Right: Specialized Agents (Legal, Sourcing, Risk) querying the central memory.
Without this orchestration, you create “Data Silos 2.0”: where the Legal AI doesn’t know what the Procurement AI has negotiated because their vector stores are disconnected.
PART II : Key Embedding Strategies for Procurement AI Agents
The term “embedding” is often used as a catch-all, but for the Data Architect and the CPO, it represents a spectrum of distinct mathematical choices. There is no single “best” embedding model; there is only the right model for the specific Procurement task.
Attempting to force a single strategy across the entire Source-to-Pay (S2P) lifecycle leads to sub-optimal performance. An agent analyzing a 50-page RFP requires a different embedding architecture than an agent categorizing line-item spend.
Here are a few core embedding strategies that procurement leaders must evaluate. Note that advanced AI Orchestration platforms like PMO1 handle this selection dynamically, but understanding the mechanics is crucial for governance.
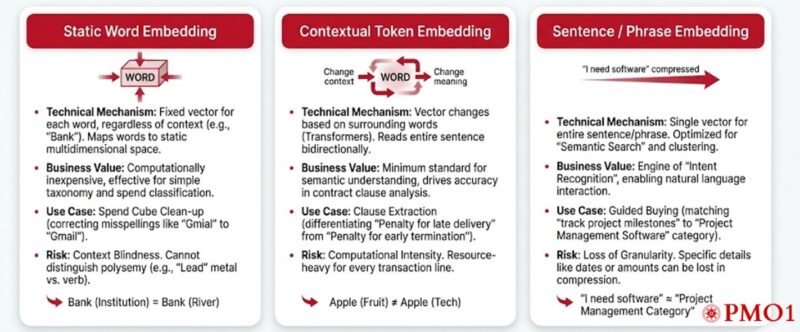
Static Word Embedding
Technical Mechanism: This is the foundational layer of natural language processing. In this model, every word is assigned a fixed vector representation regardless of where it appears. The word “Bank” has the same mathematical value whether it refers to a financial institution or a river bank. It maps words to a static multidimensional space based on co-occurrence probabilities. (Example: Word2Vec)
Business Value: While older, this strategy is computationally inexpensive and highly effective for simple taxonomy mapping and spend classification where context is low but vocabulary is specific.
Use Case: Spend Cube Clean-up. An agent using static embeddings can rapidly process millions of invoice line items to correct misspellings (e.g., mapping “Gmial” to “Gmail” or “Ofice Depo” to “Office Depot”) because the vector distance between the typo and the correct entity is negligible.
Risk: Context Blindness. It cannot distinguish polysemy. It might confuse “Lead” (the metal) with “Lead” (the verb), potentially misrouting a hazardous materials sourcing request.
Contextual Token Embedding
Technical Mechanism: Unlike static models, Contextual Token Embedding generates a vector for a word based on its surroundings. The vector for “Apple” changes depending on whether the sentence contains words like “Pie” (food context) or “MacBook” (tech context). This architecture (Transformers) reads the entire sentence bidirectionally to establish meaning. (Example: BERT)
Business Value: This is the minimum standard for semantic understanding in modern procurement. It drives accuracy in entity recognition and contract clause analysis where the meaning of a term is entirely dependent on the surrounding legal syntax.
Use Case: Clause Extraction. When a Legal Agent scans a contract for “Penalties,” it needs to differentiate between a “Penalty for late delivery” (Supplier Risk) and a “Penalty for early termination” (Buyer Risk). Contextual embeddings understand this nuance, whereas static embeddings would just flag the word “Penalty.”
Risk: Computational Intensity. These models are resource-heavy. Running them on every single line of a transaction log is inefficient and costly compared to static embeddings.
Sentence / Phrase Embedding
Symbolic Name: , Universal Sentence Encoder
Technical Mechanism: This strategy moves up a level of abstraction. Instead of embedding individual words, it creates a single vector for an entire sentence or phrase. It is optimized for “Semantic Search” and clustering. It allows the AI to calculate the similarity between two complete thoughts, rather than just matching keywords. (Example: Sentence-BERT)
Business Value: This is the engine of “Intent Recognition.” It allows stakeholders to interact with procurement systems using natural language rather than rigid drop-down menus.
Use Case: Guided Buying. A stakeholder types: “I need a way to track project milestones.” The embedding model matches this semantic intent to the “Project Management Software” category and the preferred supplier “Asana,” even though the user never used the words “Software” or “Asana.”
Risk: Loss of Granularity. In compressing a complex sentence into a single vector, specific details (like a date or a dollar amount) can sometimes be “smoothed out” or lost in the mathematical average.
The Orchestration Advantage: Why You Shouldn’t Choose Just One
The challenge for the Enterprise Architect is that a robust Procurement function requires all of these strategies simultaneously.
-
You need Static Embeddings for your master data management.
-
You need Contextual Embeddings for your contract analytics.
-
You need Sentence Embeddings for your internal chatbots.
Building a custom stack that routes every query to the correct model is a massive data science undertaking. This is the strategic value of an AI Agent Orchestration Platform.
How AI Orchestration Tools (like PMO1) Solve This:
-
Dynamic Model Routing: The platform automatically detects the nature of the task. If it’s a simple classification, it routes to a lightweight model. If it’s a complex legal review, it calls a heavy contextual model.
-
Unified Vector Store: It abstracts the storage complexity, allowing different agents to retrieve data regardless of how it was originally embedded.
-
Out-of-the-Box Optimization: Teams do not need to hire NLP engineers to tune BERT models; the suite comes pre-configured with embeddings optimized for procurement taxonomies (UNSPSC, Spend Categories).
What CPOs Must Focus On
While the orchestration platform handles the technical complexity, the CPO must focus on the Operating Model that surrounds it. The Board does not care about “Vector Dimensions”; they care about risk and speed.
Focus Area 1: Data Readiness & The “Context Gap”
The most sophisticated embedding strategy cannot fix broken data. If your historical contracts are scanned images without OCR (Optical Character Recognition), they are invisible to the model.
-
Action: Launch a “Data Digitization Sprint.” Ensure all historical knowledge is machine-readable.
-
Metric: Percentage of supplier contracts fully digitized and indexed.
Focus Area 2: Governance & The “Black Box” Problem
As we move from Static to Contextual embeddings, explainability decreases. It is harder to explain why a neural network linked two documents than it is to explain a keyword match.
-
Action: Demand “Citation Layers” in your orchestration tool. The AI must be able to highlight the specific text that drove its decision.
-
Risk: Without this, you cannot defend AI-driven sourcing decisions during an audit.
Focus Area 3: Talent Capability Uplift
Your category managers do not need to be coders, but they must become “Prompt Architects” and “Logic Auditors.”
-
Action: Update job descriptions to include “AI Literacy.” The ability to evaluate if an Agent is hallucinating or using the wrong context is now a core procurement skill.
Focus Area 4: ROI Metrics
Shift the conversation from “Headcount Reduction” to “Value Amplification.”
-
Wrong Metric: “How many buyers can we fire?”
-
Right Metric: “How much ‘Maverick Spend’ did we capture because the Buying Agent was easier to use than the corporate credit card?”
-
Right Metric: “How many risk clauses did we identify across 10,000 contracts that no human had time to read?”
Part III: The Execution Roadmap & Strategic Conclusion
The Enterprise Roadmap for Embedding Procurement AI Agents: Moving from “pilot purgatory” to an embedded, agent-first operating model requires a disciplined, phased approach. This is not a software upgrade; it is a transformation of the procurement cognitive layer.
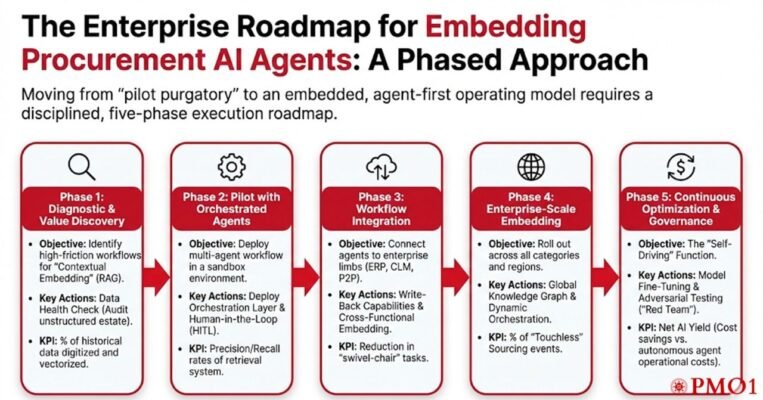
We recommend a five-phase execution roadmap designed to mitigate risk while accelerating time-to-value.
Phase 1: Diagnostic & Value Discovery
-
Objective: Identify high-friction workflows where “Contextual Embedding” (RAG) solves a specific pain point that traditional automation (RPA) cannot.
-
Key Actions:
-
Data Health Check: Audit the “unstructured” estate. Are contracts OCR-readable? Are supplier emails accessible?
-
Use Case Selection: Select one high-volume, low-risk workflow (e.g., “Level 1 Supplier Support” or “Tail Spend Categorization”).
-
Baseline Measurement: Quantify current cycle time and error rates to establish the ROI baseline.
-
-
KPI: % of historical data digitized and vectorized.
-
Risk: “Garbage In” leading to immediate hallucination. Mitigation: Strict data cleansing before ingestion.
Phase 2: Pilot with Orchestrated Agents
-
Objective: Deploy a multi-agent workflow in a “sandbox” environment using an orchestration platform.
-
Key Actions:
-
Deploy Orchestration Layer: Implement a platform (like PMO1) to manage agent handoffs.
-
Embedding Strategy Selection: Choose the specific model (e.g., Contextual Token Embedding for contracts) and index the pilot data.
-
Human-in-the-Loop (HITL): Configure the system so every agent action requires human approval.
-
-
KPI: Precision/Recall rates of the retrieval system (Did the agent find the right clause?).
-
Risk: Agent “drifting” off-topic. Mitigation: Strict system prompts and rigid output schemas (JSON enforcement).
Phase 3: Workflow Integration
-
Objective: Connect the agents to the “limbs” of the enterprise (ERP, CLM, P2P systems).
-
Key Actions:
-
Write-Back Capabilities: Allow the agent not just to read the contract, but to update the vendor master data in SAP/Oracle.
-
Cross-Functional Embedding: Integrate Legal and Finance agents into the Procurement workflow (e.g., a Legal Agent auto-approving standard NDAs requested by the Sourcing Agent).
-
Shift to “Human-on-the-Loop”: Move from requiring approval for every step to requiring approval only for final execution.
-
-
KPI: Reduction in “swivel-chair” tasks (manual data entry between systems).
-
Risk: Corrupting the ERP with bad data. Mitigation: Transactional logging and rollback capabilities.
Phase 4: Enterprise-Scale Embedding
-
Objective: Roll out across all categories and regions.
-
Key Actions:
-
Global Knowledge Graph: Federate the vector stores so a buyer in Singapore benefits from negotiation data generated in Berlin.
-
Dynamic Orchestration: Allow the orchestration platform to dynamically spin up agents based on real-time spikes in demand (e.g., during a supply shock).
-
Stakeholder Direct Access: Allow business stakeholders to chat directly with Sourcing Agents via Slack/Teams, bypassing the procurement helpdesk entirely.
-
-
KPI: % of “Touchless” Sourcing events (end-to-end automation).
-
Risk: Unchecked cloud costs from vector processing. Mitigation: Implement “Metadata Filtering” (Strategy 2) to optimize query costs.
Phase 5: Continuous Optimization & Governance
-
Objective: The “Self-Driving” Function.
-
Key Actions:
-
Model Fine-Tuning: Use the feedback data (user corrections) to retrain the embedding models for higher accuracy.
-
Adversarial Testing: Use “Red Team” agents to try and trick the procurement agents into violating policy, patching gaps proactively.
-
-
KPI: Cost savings vs. autonomous agent operational costs (Net AI Yield).
The Inevitability of the Agentic Enterprise
The window for viewing Generative AI as a “productivity toy” has closed. We are witnessing a bifurcation in the procurement landscape:
-
Legacy Organizations that use AI as a faster typewriter—accelerating manual tasks but retaining the old operating model.
-
Next-Generation Enterprises that embed AI agents into the fabric of the function—building a new operating model where human capital is elevated to strategy, relationship management, and innovation.
The friction that currently plagues procurement—the slow response times, the lost knowledge, the opaque spend—is not a software problem; it is an architecture problem. It stems from the inability of rigid systems to understand fluid business context.
By adopting robust Embedding Strategies and leveraging AI Orchestration Platforms like PMO1, CPOs can finally bridge this gap. They can build a function that remembers every negotiation, understands every contract, and acts with the speed of software and the nuance of a seasoned buyer.
The technology is ready. The embedding strategies are defined. The only remaining variable is leadership courage.
Also See:
Guide to Chunking in Procurement AI
On Premise Vs Cloud TCO Calculator
Inference Benchmarks (Output Tokens/Sec)
PMO1 is the Local AI Agent Suite built for the sovereign enterprise. By deploying powerful AI agents directly onto your private infrastructure, PMO1 enables organizations to achieve breakthrough productivity and efficiency with zero data egress. We help forward-thinking firms lower operational costs and secure their future with an on-premise solution that guarantees absolute control, compliance, and independence. With PMO1, your data stays yours, ensuring your firm is compliant, efficient, and ready for the future of AI.