{kind=link}
vLLM vs. Ollama: Choosing the Right LLM Inference Runtime for Self-Hosted Enterprise AI
In the transition from “AI-as-a-feature” to “AI-as-infrastructure,” the selection of an inference runtime determines your platform’s ceiling regarding throughput, cost-efficiency, and operational reliability. As Enterprise Architects, we must view Large Language Model (LLM) inference not as a secondary application feature, but as a core platform primitive. In this article, we provide a rigorous architectural comparison between Ollama and vLLM, specifically for self-hosted, sovereign, or air-gapped enterprise environments.
“Just running a model” is trivial; maintaining a high-availability, multi-tenant inference layer that survives bursty production traffic is an entirely different engineering discipline.
Reference Architecture Context
The baseline for this analysis is a self-hosted, containerized AI stack designed for data sovereignty and internal service consumption.
In this architecture, the LLM Inference Layer (currently occupied by Ollama) acts as the engine for the n8n workflow orchestrator. It consumes requests via a Reverse Proxy (Caddy/Traefik), pulls context from the Qdrant Vector Database, and persists state in PostgreSQL.
While this setup is ideal for rapid prototyping and internal productivity tools, scaling it to enterprise-wide demand requires evaluating whether Ollama’s “ease-of-use” philosophy introduces a performance bottleneck or if a more high-throughput engine like vLLM is required.
Ollama: Architectural Characteristics
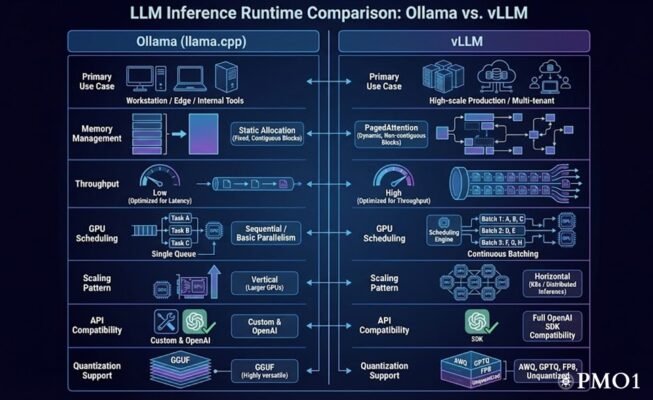
Ollama has gained massive traction by abstracting the complexities of model weights, quantizations, and environment configurations into a single, cohesive binary.
Runtime Design Philosophy
Ollama is built on llama.cpp, focused on accessibility and local development. It treats models as “images” (similar to Docker), bundling weights, configuration, and templates into a single manifest. It is designed to run as a persistent background service that manages model loading and unloading dynamically.
API Model and Integration
Ollama provides a proprietary REST API alongside an OpenAI-compatible endpoint. Its integration with tools like n8n is seamless because it handles the complexities of prompt templating internally. However, its API is primarily designed for unary requests (one-to-one) rather than high-concurrency batching.
Strengths in the Referenced Architecture
-
Zero-Config Model Management: Simplifies the Model Lifecycle Management by handling GGUF quantizations and hardware discovery automatically.
-
Low Entry Barrier: Perfect for the “local network” Docker environment shown in the reference, where developer velocity outweighs raw throughput.
-
Resource Efficiency: It can aggressively offload layers to CPU if GPU VRAM is saturated, ensuring the service doesn’t crash, albeit at the cost of performance.
Known Limitations
Ollama’s primary architectural weakness in an enterprise context is its lack of native continuous batching. While it can handle multiple requests, it does not optimize GPU utilization via advanced scheduling algorithms, leading to significantly lower Total Token Throughput compared to vLLM.
vLLM: Architectural Characteristics
vLLM is a high-throughput, serving-optimized library designed specifically for production environments where GPU compute is the scarcest and most expensive resource.
PagedAttention and Batching Model
The core innovation of vLLM is PagedAttention. Traditional inference engines waste significant GPU memory by pre-allocating contiguous blocks for the KV (Key-Value) cache. vLLM treats KV cache memory like virtual memory in an OS, partitioning it into non-contiguous blocks. This allows for near-zero memory waste, enabling significantly larger batch sizes.
GPU Efficiency and Throughput
By utilizing Continuous Batching, vLLM doesn’t wait for a whole batch to finish before starting the next request. This results in 10x–20x higher throughput than standard llama.cpp-based implementations under heavy load.
Operational Complexity
Unlike Ollama’s “one-click” experience, vLLM is a Python-based library (often deployed via an official Docker container). It requires explicit configuration of GPU memory utilization targets, tensor parallelism, and model sharding across multiple GPUs.
vLLM vs. Ollama – Quick Architectural Comparison
Integration with the Referenced Architecture
When replacing Ollama with vLLM in the provided Docker environment, the architectural “center of gravity” shifts from simplicity to performance.
From Ollama to vLLM: Structural Changes
-
Orchestration: While n8n connects to Ollama via a dedicated node, it would connect to vLLM using the OpenAI Chat completion node.
-
Reverse Proxy Considerations: vLLM’s high-concurrency nature requires the Reverse Proxy (Traefik/Caddy) to handle long-lived connections and potentially larger request headers.
-
Storage: vLLM typically loads unquantized (HuggingFace format) or AWQ/GPTQ models. This requires larger Docker Volumes and faster disk I/O compared to Ollama’s GGUF files.
Vector DB and RAG Implications
In a RAG (Retrieval-Augmented Generation) pipeline using Qdrant, vLLM’s throughput becomes a massive advantage. If n8n triggers a batch process (e.g., summarizing 100 documents retrieved from Qdrant), Ollama will process these linearly, causing a massive queue. vLLM will batch these requests, saturating the GPU and completing the job in a fraction of the time.
Security, Isolation, and Governance
In a Zero Trust regulated environment, the inference runtime is a critical security boundary.
-
Attack Surface: Ollama runs a management API that allows model pulling/deletion. In production, this must be disabled or protected behind strict MTLS (Mutual TLS). vLLM’s API is purely for inference, which inherently reduces the “management” attack surface.
-
Multi-tenancy: vLLM supports Multi-LoRA (Low-Rank Adaptation) serving. This allows a single vLLM instance to serve multiple specialized versions of a base model for different departments, maintaining logical isolation without the overhead of multiple GPU instances.
-
Auditability: vLLM provides more granular Token-level metrics (Time to First Token, Inter-token latency), which are essential for internal chargeback models and compliance monitoring.
Decision Framework
Choose Ollama When:
-
You are building internal productivity tools or RAG prototypes with low concurrent user counts (< 5-10).
-
Your environment has constrained or heterogeneous hardware (e.g., Apple Silicon, mixed NVIDIA/AMD, or CPU-only fallbacks).
-
You require a “Model Store” experience where users can easily swap models via an API.
Choose vLLM When:
-
You are deploying a Production AI Platform serving hundreds of users or automated agents.
-
GPU Utilization is a KPI. If you are paying for an A100/H100, Ollama will leave 70% of the compute idle; vLLM will saturate it.
-
You are running on Kubernetes (K8s). vLLM scales horizontally much better and integrates with tools like KServe or SkyPilot.
-
You need Tensor Parallelism to run models larger than a single GPU’s VRAM (e.g., Llama-3-70B across two A10s).
Architectural Fit Over Hype
There is no “best” runtime, only the runtime that fits your constraints. Ollama is the champion of the “Local Network” and developer experience, making it the perfect starting point for the referenced architecture. However, as the workload migrates from a single n8n workflow to a cross-departmental platform, the architectural overhead of vLLM becomes a necessary investment to ensure scalability, throughput, and efficient GPU stewardship.
As Enterprise Architects, our role is to ensure that the infrastructure doesn’t just “work,” but that it is architected for the failure modes and scaling realities of 2026 and beyond.
—————————
PMO1 is the Local AI Agent Suite built for the sovereign enterprise. By deploying powerful AI agents directly onto your private infrastructure, PMO1 enables organizations to achieve breakthrough productivity and efficiency with zero data egress. We help forward-thinking firms lower operational costs and secure their future with an on-premise solution that guarantees absolute control, compliance, and independence. With PMO1, your data stays yours, ensuring your firm is compliant, efficient, and ready for the future of AI.